로그 이상감지에 대해 알아봅시다
이번 포스팅에서는 AIOps의 중요한 부분 중 하나인 로그 이상감지라는 분야에 대해서 다뤄보도록 하겠습니다.
1. 로그 데이터?
다음과 같은 화면을 보신적 있으신가요?
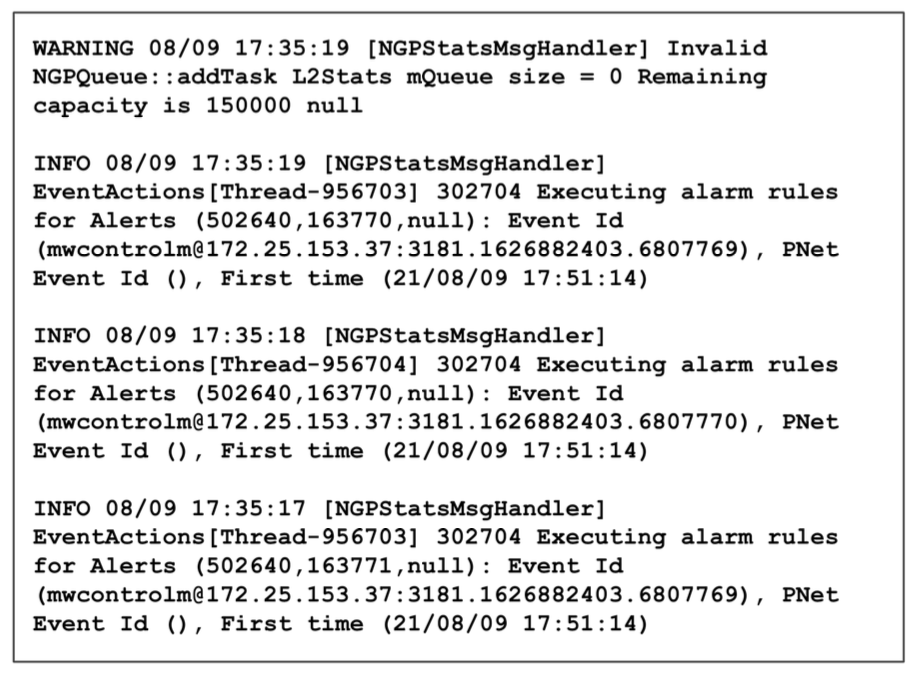
소프트웨어 로그는 소프트웨어 개발자가 유지 관리 목적으로 설계한 시스템 내 프로세스에 대한 런타임 정보의 기록입니다.
로그는 일반적으로 반정형 데이터입니다. 즉, 로그에는 구조화된 데이터와 구조화되지 않은 데이터가 함께 포함됩니다.
- 구조화되지 않은 부분 : 자연어 토큰, 프로그래밍 언어 구성(ex. 메서드 이름) 등
- 구조화된 부분 : 소스코드의 로깅 명령문, 로거 또는 로깅 에이전트를 통해 생성되는 양적 또는 범주형 데이터
그리고 로그를 생성하는 서비스의 유형에 따라 다양한 형태와 내용을 가진 로깅 데이터가 존재할 수 있습니다. 이는 범용성 있는 전처리 모델을 개발하는데 정말 어려운 부분입니다..
2. 로그 이상감지란 무엇일까요?
로그 파일은 컴퓨터 시스템을 모니터링할 때 풍부한 정보 소스를 제공합니다. 따라서 대부분의 로그 이벤트는 일반적으로 프로세스 시작 및 중지, 가상 머신 재시작, 사용자 리소스 액세스 등과 같은 정상적인 시스템 작동의 결과로 생성됩니다.
그러나 애플리케이션은 프로세스 실패, 가용성 문제, 보안 사고 등 결함이 있거나 원치 않는 시스템 상태가 발생할 때에도 로그를 생성합니다. 이러한 예기치 못한 안전하지 않은 시스템 활동의 흔적은 시스템 운영자가 적시에 조치를 취하여 시스템 손상을 방지하거나 줄이고 연쇄적인 악영향을 피해야 하는 시스템 운영자에게 중요합니다.
하지만 결함이 발생했을 때 시스템 운영자가 한땀한땀 로그를 확인하기는 현실적으로 불가능합니다. 정말 많은 로그가 쌓이기 때문이죠. 그렇기 때문에 자동으로 로그에서 이상을 탐지하고 운영자에게 알람을 주는 것이 필요합니다.
따라서 로그의 이상을 정의하고 탐지하는 것은 AIOps의 중요한 부분 중 하나라고 말할 수 있고, 제가 속한 팀에서도 중요하게 여기고 있습니다.
3. 무엇을 탐지하나요?
그렇다면 무엇이 이상한 로그일까요? AIOps에서 로그의 이상은 다음과 같이 정의할 수 있을 것 같습니다.
- keywords : 시스템의 장애, 사고 또는 이상에 대한 도메인별 의미를 나타내는 로그 라인에 키워드가 표시됨.
- template count : 로그 이벤트 유형의 급격한 증가 또는 감소는 이상 현상을 나타냄.
- template sequence : 일반적인 작업 순서에서 벗어나는 것은 이상 현상일 수 있다.
- variable distribution : 일부 범주형 또는 수치형 변수의 경우 변수의 표준 분포에서 벗어나면 이상일 수 있다.
- variable value : 일부 로그 이벤트와 관련된 일부 변수는 물리적 의미를 가질 수 있으며, 이를 추출하여 시계열 이상감지를 적용할 수 있다.
- time interval : 일부 성능 문제는 로그라인 자체가 아니라 특정 로그 이벤트 사이의 시간 간격에서 관찰될 수 있다.
하지만 이밖에도 도메인 또는 서비스마다 필요한 이상의 정의를 각자 정의할 수 있을 것 같습니다.
4. 로그 이상감지
그럼 본격적으로 데이터사이언스 관점에서 로그 이상감지에 대해 알아보도록 하겠습니다.
로그 이상감지는 보통 아래 그림과 같은 과정으로 구성되어 있습니다.
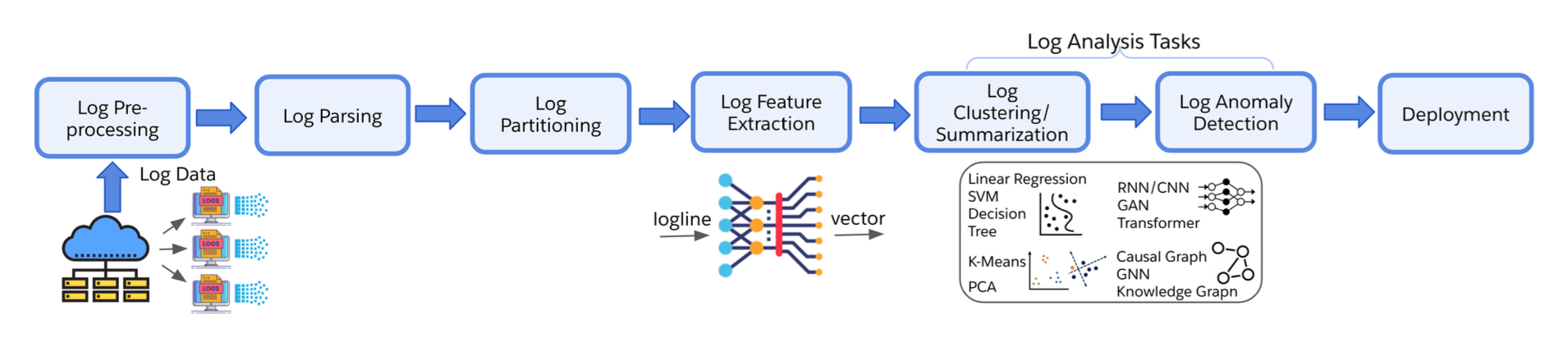
IT 운영 프로세스에서 생성되는 로그는 굉장히 복잡합니다. 이 로그를 의미있게 분석하여 이상을 탐지하려면 일련의 과정이 필요합니다.
사전에 전처리를 하여 반정형 데이터에서 특정 구조를 추출하고 로그 라인들을 그룹화하여 데이터의 시퀀스 특성을 파악할 수 있습니다.
4.1. 전처리 방법
로그를 전처리하는 연구는 다양하게 진행되는 것 같습니다. 그 중 저희 팀이 했던 방법을 위주로 설명하려고 합니다.
(1) Log Preprocessing
먼저 전처리 부분입니다. 이 단계에서는 일반적으로 실제 로그 분석과 관련이 없는 것으로 간주되는 특정 정규식 패턴(ex. IP주소 또는 메모리경로 등)에 대한 사용자 지정 필터링을 수행합니다. 또한 datetime등에 대해서도 분석하기 쉽게 처리를 진행하기도 합니다.
(2) Log Parsing
Log Parsing이란 구조화되지 않은 로그 메세지를 구조화된 이벤트 템플릿과 매개변수로 파싱하는 것을 뜻합니다.

위 그림은 단일 로그를 파싱하는 예시입니다. 로그에서 datetime값, 로그 level, template등을 추출할 수 있습니다. 여기서 template부분에서 <*>로 마스킹처리된 부분은 파라미터 부분으로 따로 저장하여 파라미터분석을 진행할 수도 있습니다.
그런데 왜 template 부분에서 <*>로 마스킹처리된 부분이 있을까요? 그 이유는 template에 힌트가 있습니다. 예를 들어,
1. ABC1DE
2. ABC2DE
이런 두개의 로그가 있다고 가정했을 때 두개의 로그를 다른 로그라고 지정해버리다면 로그의 종류는 너무 많아서 분석하기 어려울 것 같습니다. 이를 방지하기 위해 마스킹처리를 하여 같은 로그로 지정할 수 있도록 처리를 해줄 수 있습니다.
그럼 이러한 로그 파싱을 진행하는데는 어떤 알고리즘이 사용될까요? 일반적으로 Drain, Spell을 많이 사용한다고 합니다. 저희 팀에서도 Drain을 통해 연구를 진행하고 있습니다. Drain에 대한 자세한 설명은 추후에 다룰 기회가 있을 것 같습니다.
이러한 로그파싱을 통해 로그라인은 시퀀스 특성을 가지는 데이터로 활용할 수 있게 됩니다. 예를 들어,
Template
A : 로그<*>안녕하세요
B : 로그<*>안녕히계세요
실제 로그
1. 로그1안녕하세요
2. 로그2안녕하세요
3. 로그1안녕히계세요
4. 로그2안녕히계세요
와 같이 템플릿이 완성되었을 때 실제로그는 AABB와 같이 표현할 수 있고 이 데이터를 모델링할 때 활용할 수 있습니다. 여기서 A와 B를 log key라고 부릅니다.
위에서 소개한 drain의 경우 휴리스틱한 방법론인데 최근 log parsing을 위한 딥러닝 기술에 대한 연구도 활발히 진행되고 있는 것 같습니다. 그 중 다양한 시스템의 다양한 로그를 일반화하는 UniParser가 있습니다.
(3) Log Representation
그럼 이렇게 로그를 파싱한 후의 데이터를 어떻게 활용하면 좋을까요?
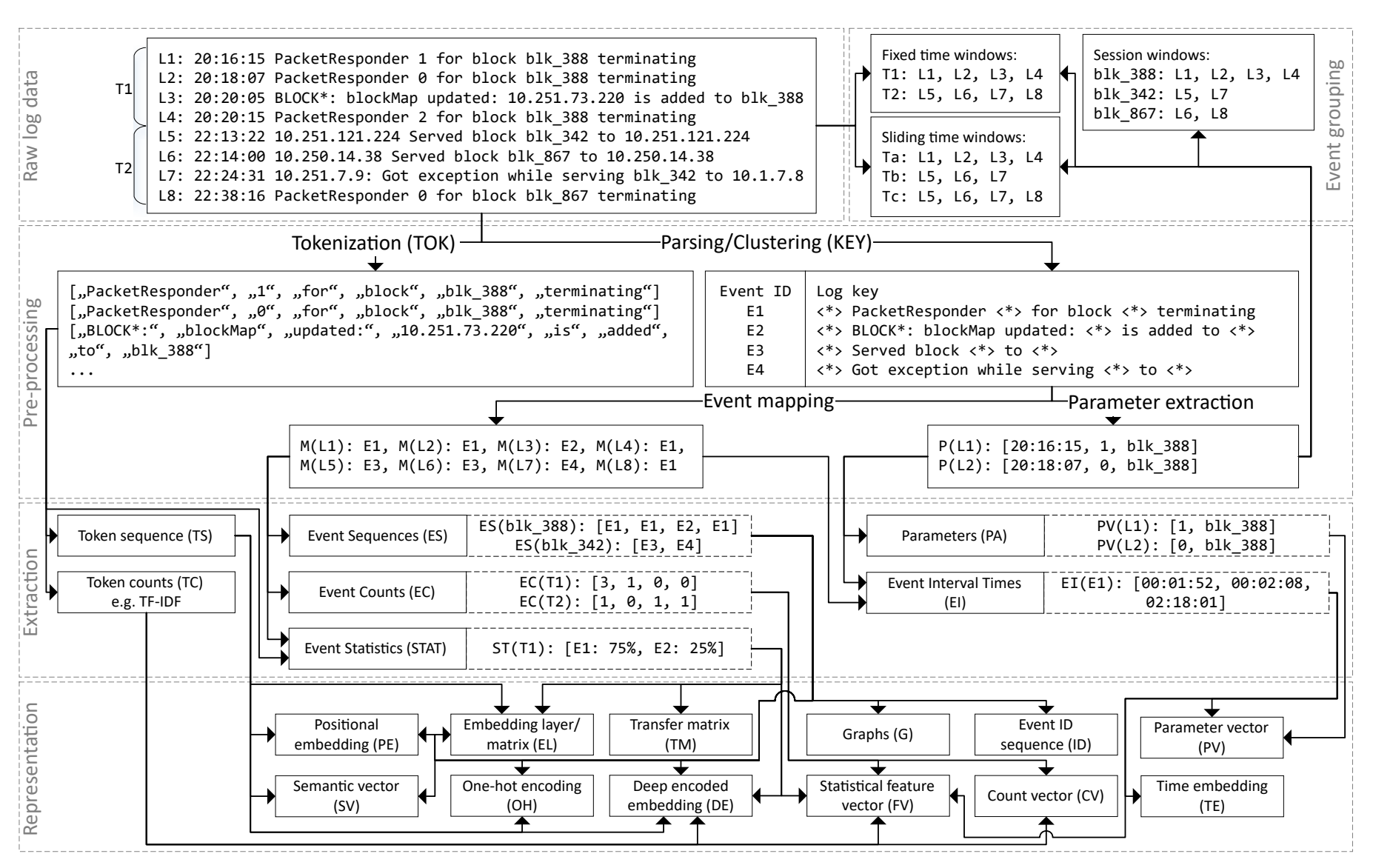
위 그림은 로그의 다양한 representation 방법에 대한 도식화입니다. 이러한 다양한 방법들을 통해 원하는 task와 적절한 모델의 input으로 활용할 수 있습니다.
저희팀의 경우 실시간 처리의 우선순위가 높았기 때문에 로그키까지만 활용했었지만 딥러닝 모델을 활용할 경우 윈도우를 어떻게 분할할지 등에 대한 representation에 대한 전략이 중요합니다.
4.2. 어떤 알고리즘을 사용하나?
그럼 로그 이상감지에서는 어떤 알고리즘을 사용할까요?
사실 이 질문의 답변은 로그의 이상을 어떻게 정의하냐에 따라 달라질 것 같습니다. 그럼 위에서 정의한 이상에 대해서 어떤 알고리즘을 써야할지 고민해봅시다.
(1) keywords
keywords anomaly는 특정 키위드가 로그 라인에 표시되면 탐지해야합니다. 그렇다면 복잡한 모델을 사용하기보단 정규식처리 등을 통해 미리 정의된 키위드를 검색하는 간단한 방법으로도 처리가 가능할 것 같습니다.
(2) template count
로그 이벤트 유형의 급격한 증가 또는 감소를 탐지하기 위해서는 일단 데이터를 시계열데이터로 변환한다면 좋을 것 같습니다. 그 이후 통계적 방법으로 분포에서 동떨어진 데이터를 찾거나 AutoEncoder와 같은 방법을 통해 이상을 탐지할 수 있을 것 같습니다.
(3) template sequence
어떤 로그들은 순서가 중요할 수 있습니다. 예를 들어 A, B, C, D 이런 순으로 기록되던 로그가 A, C, B, D와 같이 순서가 틀어진다면 이를 이상으로 정의하고 탐지해야합니다. 그럼 이런 이상을 어떻게 탐지하면 좋을까요?
딥러닝 방법으로는 RNN과 같은 시퀀셜모델이 떠오릅니다. 시퀀셜모델은 특정 단어 다음에 어떤 단어가 나올지 예측하는 방식을 학습하기 때문입니다. 대표적인 모델로 DeepLog가 있습니다. 또는 transformer와 같은 attention 계열 모델들도 활용할 수 있겠습니다. 대표적으로 LogBert라는 모델이 있습니다.
통계모델로는 어떤 모델을 활용하면 좋을까요? 마코프 체인이 좋은 방법이 될 수 있을 것 같습니다. 마코프 체인이란 한 상태에서 다른 상태로 이전을 할 때 특정한 확률적 특성을 따르는 것을 의미합니다. 이를 적용한다면 특정 로그들의 순서도 특정한 확률이 있음을 포착할 수 있습니다.
(4) variable distribution, variable value
위의 log parsing부분에서 마스킹처리에 대해 다뤘습니다. 마스킹처리한 부분을 파라미터로 저장할 수 있는데 이 파라미터들도 성격에 따라 분석할 수 있습니다. 예를 들어 마스킹처리한 부분이 지연률이고, 지연률이 특정 분포를 넘어서게 된다면 알람을 줘야할 수도 있습니다.
이러한 이상들도 template count와 같이 통계적 방법등으로 해결할 수 있습니다.
(5) time interval
특정 로그는 특정한 시간간격으로 기록될 수 있습니다. 예를 들어 crontab log가 있습니다. 이러한 로그가 다른 시간대에 발생했으면 문제가 있는 것일 수 있기 때문에 탐지해줘야 합니다.
그럼 어떻게 탐지할 수 있을까요? 이런 로그들은 datetime이 중요합니다. 시간 간격을 알아야하기 때문이죠. 시간간격의 분포를 확인하고 분포에서 떨어졌다면 알람을 발생하는 방식으로 해결할 수 있습니다.
마무리
로그이상감지는 한계점 또는 과제도 분명합니다.
시계열 이상감지와 마찬가지로 라벨링된 데이터가 부족하기 때문에 지도학습을 하기 어렵습니다. 만약, 라벨링된 데이터가 있다 하더라도 클래스의 불균형문제도 있죠.
또한 로그데이터는 단시간에 수많은 데이터가 수집되기 때문에 대용량 데이터에 대한 처리도 중요합니다.
또한 좀 더 정교한 로그언어모델의 개발이 필요합니다. 그리고 다양한 형태의 로그파일들을 통합할 수 있는 연구도 필수적입니다.
댓글남기기