사용자 선호를 학습하는 LLM 만들기
LLM은 다음 단어를 예측하는 방식으로 대량의 텍스트를 학습해서 뛰어난 텍스트 생성 능력을 보여줬습니다.
2020년 OpenAI가 GPT-3를 발표했을 때 생성 결과의 퀄리티는 좋았지만, 사용자의 요청에 적절히 응답하기보다는 사용자의 말에 이어질 법한 텍스트를 생성한다는 한계를 지니고 있었습니다.
그렇다면 GPT-3는 어떻게 ChatGPT가 될 수 있었을까요?
Open-AI는 두 단계를 거쳐 GPT-3를 ChatGPT로 변화시켰습니다. 먼저, 요청(또는 질문)과 답변 형식으로 된 instruction dataset을 통해 GPT-3가 사용자의 요청에 응답할 수 있도록 학습시켰습니다. 다음으로 사용자가 더 좋아하고 사용자에게 더 도움이 되는 답변을 생성할 수 있도록 추가학습을 시켰습니다. 이를 사용자 선호를 학습한다고 합니다.
선호를 학습한 LLM은 더 정제된 답변을 생성하게 됩니다.
이번 포스팅에서는 사람들이 더 선호하는 답변을 생성할 수 있도록 모델을 조정하는 방법에 대해 알아봅니다.
사전 학습과 fine tuning
1. LLM의 사전 학습
LLM은 보통 인터넷상에 있는 다양한 텍스트 데이터를 수집한 대용량의 텍스트로 사전 학습합니다.
2023년 메타가 공개한 LLama-2는 약 10TB 분량의 텍스트를 사전 학습에 사용했는데 이 데이터의 경우 코드, 블로그, 기사, 광고 등 다양한 글이 섞여 있기 때문에 사전 학습 데이터에서 다음 단어를 예측하는 방법으로 학습하는 경우 LLM이 특정한 형태로 응답하거나 사용자의 요청에 따라 응답하길 기대하기는 어렵습니다.
사전 학습 동안 LLM이 언어에 대한 전체적인 이해도가 높아지고 바로 다음에 올 단어를 점점 더 잘 예측하게 됩니다.
2. Supervised fine-tuning
LLM이 사용자의 요청에 적절히 응답하기 위해서는 요청의 형식을 적절히 해석하고, 응답의 형태를 적절히 작성하며, 요청과 응답이 잘 연결되도록 추가로 학습해야합니다. 이를 supervised fine-tuning이라고 합니다. 여기서 supervised는 학습 데이터에 정답이 포함되어 있다는 의미입니다. supervised fine-tuning를 통해 LLM은 사용자 요청에 맞춰 응답하도록 학습하는데, 이를 alignment라고 합니다. 사람의 요청과 LLM의 응답이 정렬되도록 한다는 의미죠.
이 때 사용하는 데이터셋을 instruction dataset이라고 합니다. 많고 질 좋은 이 데이터셋을 구하기는 굉장히 힘듭니다. 이런 문제를 보완하기 위해 사용자의 요구사항과 그에 대단 응답을 구조화한 데이터를 구축하고 언어 모델의 학습에 활용합니다. 2023년 스탠퍼드에서 오픈소스 Llama 모델을 추가 학습한 Alpaca를 공개할 때 사용한 알파카 데이터셋을 살펴보죠.
{
"instruction": "Create a classification task by clustering the given list of items.",
"input": "Apples, oranges, bananas, strawberries, pineapples",
"output": "Class 1: Apples, Oranges\nClass 2: Bananas, Strawberries\nClass 3: Pineapples",
"text": "Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.\n\n### Instruction:\nCreate a classification task by clustering the given list of items.\n\n### Input:\nApples, oranges, bananas, strawberries, pineapples\n\n### Response:\nClass 1: Apples, Oranges\nClass 2: Bananas, Strawberries\nClass 3: Pineapples",
}
instruction은 사용자의 요구사항을 표현한 문장입니다. input에는 답변을 하는 데 필요한 데이터가 들어가고, output은 정답 응답, text에는 instruction, input, output을 정해진 포맷으로 하나로 묶은 데이터입니다.
위 예시는 아직 특정한 형식을 갖추지는 않았는데, 아래같은 템플릿 형태로 맞춰줍니다. 이때 LLM이 데이터의 형식을 인식할 수 있도록 ###으로 텍스트를 구분합니다.
f"""
Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
Create a classification task by clustering the given list of items.
### Input:
Apples, oranges, bananas, strawberries, pineapples
### Response:
Class 1: Apples, Oranges
Class 2: Bananas, Strawberries
Class 3: Pineapples
"""
이제 LLM이 사람이 더 선호하는 방식으로 답변할 수 있도록 조정하는 방식을 알아보겠습니다.
채점 모델로 가독성 높이기
1. 선호 데이터셋을 사용한 채점 모델 만들기
사람이 더 선호하는 데이터를 선택한 데이터셋을 preference dataset(선호 데이터셋)이라고 합니다. 선호 데이터와 비선호 데이터는 정해진 것은 아니고 비교하는 대상에 따라 달라질 수 있습니다. OpenAI도 chatGPT를 개발하는 과정에서 이와 같은 학습방법을 사용했습니다. fine-tuning을 마친 LLM은 사용자의 요청에 맞춰 응답하기에 사용자에게 해가 될 수 있는 정보를 제공하는 등 문제가 있는데, 이러한 부분을 줄이기 위해 생성된 답변의 점수를 평가하는 리워드 모델을 만들었습니다.
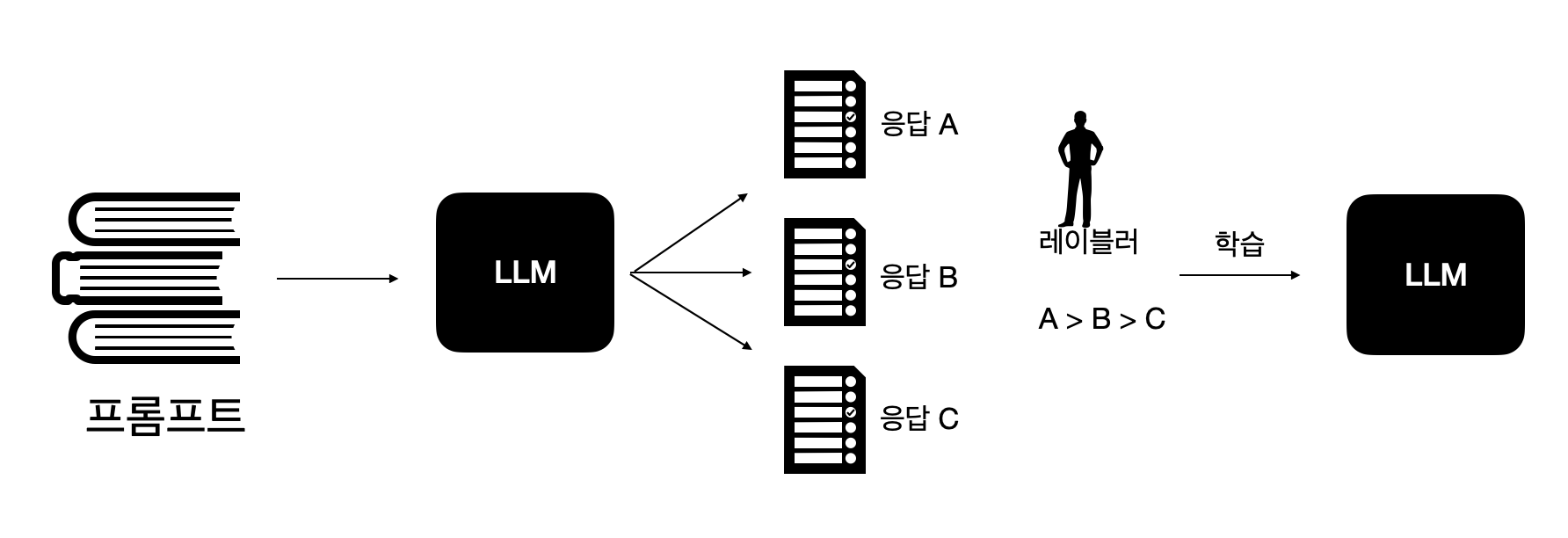
위 그림에서는 레이블러가 A > B > C 순서로 좋다 판단했고, 이렇게 구축한 선호 데이터셋을 사용해 리워드 모델이 A의 점수가 가장 높도록 학습합니다.
2. 강화학습
OpenAI는 2022년 Training Langguage models to follow instructions with human feedback이라는 논문에서 강화 학습을 사용해 LLM이 리워드 모델로부터 더 높은 점수를 받도록 학습시킨 과정을 공개했습니다. 강화학습을 사용했기 때문에 이 학습 방법을 ‘Reinforcement Learning from Human Feedback(RLHF)’라고 부릅니다.
위 그림과 같이 강화학습에서는 agent가 environment에서 action을 합니다. action에 따라 environment의 state가 바뀌고 action에 대한 reward가 생기는데, agent는 이 변화된 state를 인식하고 보상을 받습니다. agent는 가능하면 더 많은 보상을 받을 수 있도록 action을 수정하면서 학습하는데 이때 agent가 연속적으로 수행하는 action의 모음을 episode라고 합니다.
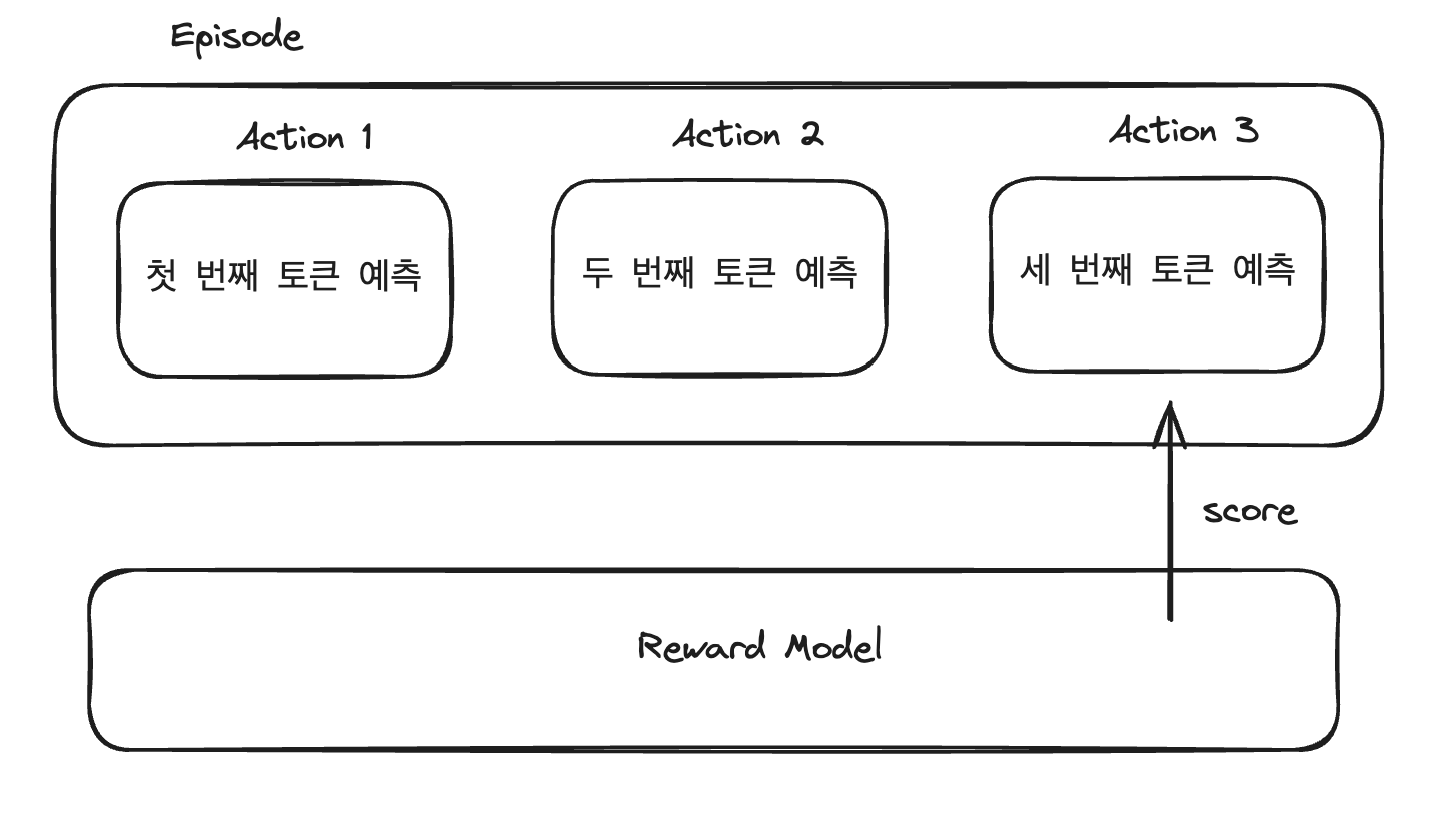
언어 모델이 RLHF를 통해 학습하는 과정인 위 그림도 봐봅시다. 언어 모델은 다음 단어를 예측하는 방식으로 토큰을 하나씩 생성하는데, 강화 학습 관점에서는 토큰 생성을 하나의 action으로 볼 수 있습니다. 언어 모델이 텍스트를 모두 생성하면, 리워드 모델이 생성한 텍스트를 평가하고 점수를 매깁니다.
이와 같은 방식으로 언어 모델은 생성한 문장의 점수가 높아지는 방향으로 학습합니다. 그런데 이때 보상을 높게 받는 데에만 집중하는 reward hacking이 발생할 수 있습니다. 예를 들어, 친절한 답변에 보상을 준다할 때 언어모델은 실질적 정보는 주지않고 친절한 어조만 반복할 수 있습니다. OpenAI는 reward hacking을 피하기 위해 PPO라는 강화학습 방법을 사용했습니다. 이제 PPO에 대해 알아봅시다.
3. PPO: Reward hacking 피하기
OpenAI는 reward hacking을 피하기 위해 강화 학습 방법 중 ‘Proximal Preference Optimization(PPO)’라는 학습 방법을 사용했습니다. PPO의 proximal은 ‘몸쪽의, 가까운’이라는 뜻이 있습니다.
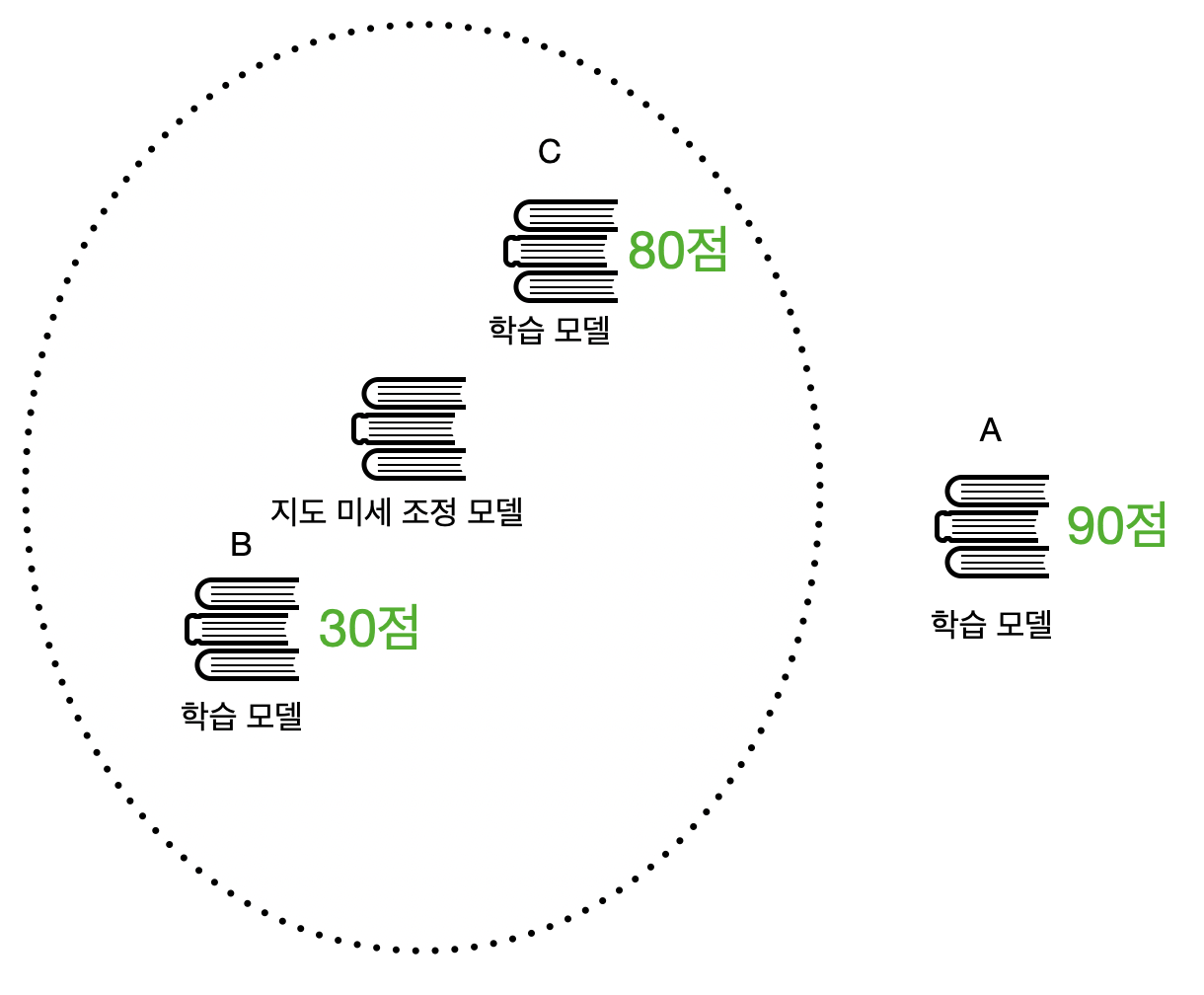
위 그림에서 가운데 있는 지도 미세 조정 모델을 기준으로 학습하는 모델이 너무 멀지 않게 가까운 범위에서 리워드 모델의 높은 점수를 찾도록 한다는 의미입니다. 이때 지도 미세 조정 모델을 기준으로 거리를 측정하기 때문에 참고모델이라고 합니다. 위 그림에서 모델 A는 점수가 90점이지만 참고 모델에서 멀어 다른 능력이 떨어지는 reward hacking이 발생했습니다. C가 참고모델에서 가까우면서도 점수가 높고, PPO는 C를 찾을 수 있습니다.
4. RLHF: 가능하면 피하고싶다
RLHF는 대화형 AI 모델을 개발하기 위한 필수 기술로 여겨졌습니다. 하지만 RLHF는 멋진 결과물만큼이나 사용하기 어렵습니다. RLHF를 사용하기 위해서는 리워드 모델을 학습시켜야 하는데, 성능이 높고 일관성 있는 리워드 모델을 만들어야 합니다. 또한 모델을 학습시킬 참고모델, 학습모델, 리워드 모델 총 3개의 모델이 필요하기 때문에 GPU와 같은 리소스가 많이 필요합니다. 지금부터는 강화 학습을 사용하지 않고 사람의 선호를 학습할 수 있는 기술에 대해 살펴봅시다.
강화학습이 꼭 필요할까
1. Rejection Sampling (기각 샘플링)
기각 샘플링은 지도 미세 조정을 마친 LLM을 통해 여러 응답을 생성하고 그중에서 리워드 모델이 가장 높은 점수를 준 응답을 모아 다시 지도 미세 조정을 수행합니다. 강화 학습을 사용하지 않기 때문에 학습이 비교적 안정적이고 간단하고 직관적입 방법임에도 효과가 좋아 많이 활용됩니다.
2023년 공개된 메타의 Llama2도 학습 과정에서 기각 샘플링을 사용했다고 합니다.
2. DPO
좋은 리워드 모델을 만들고 관리하는 것은 쉽지 않은 일입니다. 또한 리워드 모델을 만든다고 하더라고 리워드 모델에 강화 학습으로 사람의 선호를 반영한다는 것도 쉽지 않죠. 2023년 스탠퍼드 연구진이 리워드 모델과 강화 학습을 사용하지 않고 선호 데이터셋을 직접 학습하는 DPO(Direct Preference Optimization)를 발표했습니다. DPO 방법은 RLHF에 비해 훨씬 단순하면서 효과적이어서 많이 사용됩니다. RLHF와 DPO를 비교하면 아래 그림과 같습니다. RLHF는 선호 데이터셋으로 리워드 모델을 만들고 언어 모델의 출력을 평가하면서 강화 학습을 진행합니다. 하지만 DPO에서는 선호 데이터셋을 직접 언어 모델에 학습시킵니다.
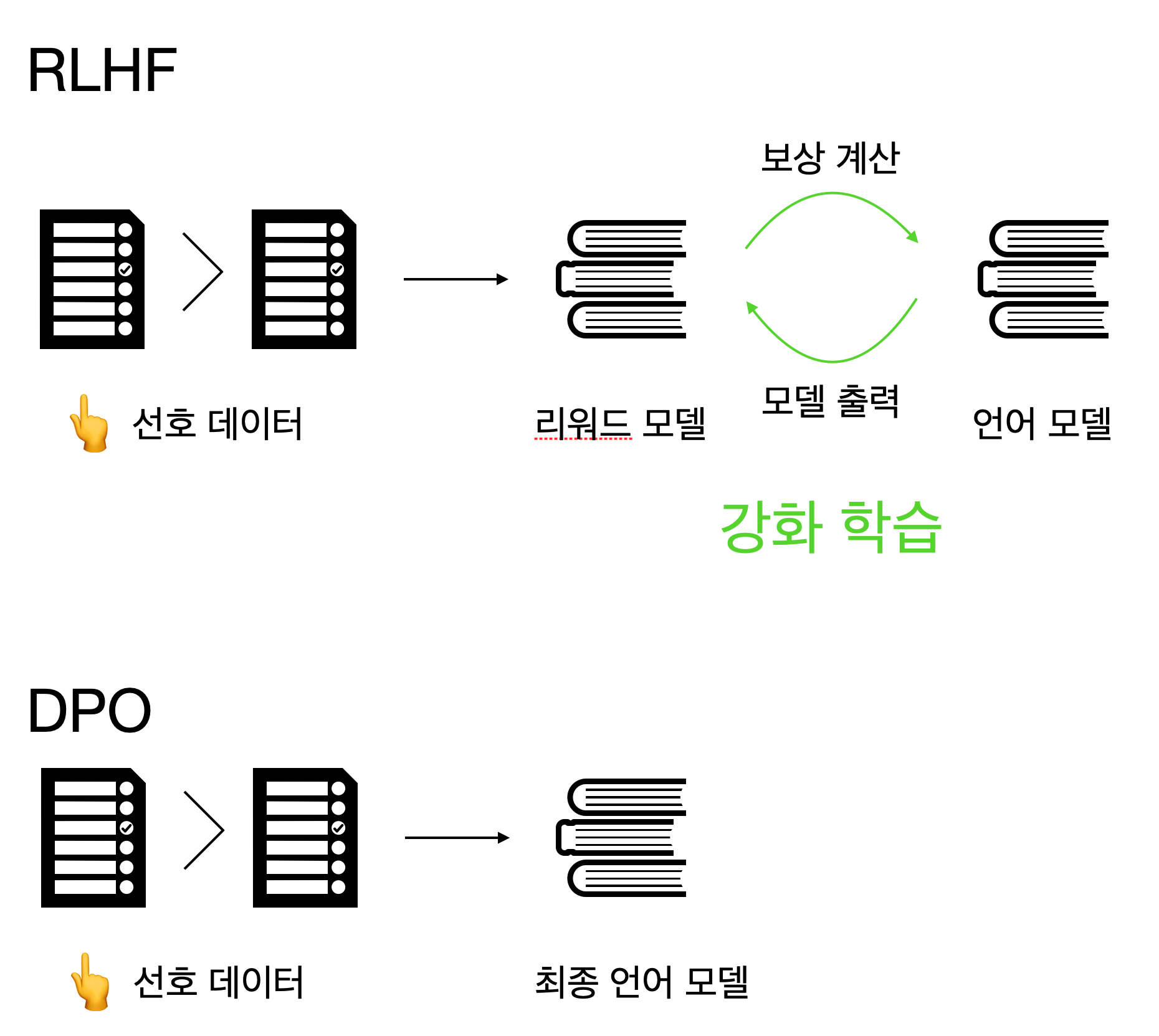
언어 모델은 다음에 올 토큰의 확률을 예측합니다. 그리고 우리에게는 프롬프트에 대해 어떤 응답이 선호되고 선호되지 않는지 데이터를 수집한 선호 데이터셋이 있다고 가정해봅시다. DPO에서는 이 두 가지를 결합해 선호 데이터셋을 직접 학습합니다. DPO는 학습이 잘되고 있는지를 확인하기 위해 학습하지 않는 학습 전 모델인 참고 모델과 비교합니다. 선호 학습을 할 때는 일반적으로 참고 모델을 지도 미세 조정을 마친 모델을 사용합니다. 선호 데이터셋에 있는 여러 데이터에 대해 이런 과정을 반복하면, 언어 모델을 점차 선호 데이터를 자주 생성하고 비선호 데이터를 드물게 생성해, 선호 데이터에 가까운 결과를 생성하는 언어모델이 됩니다.
위 그림과 같이 DPO 학습을 위해서는 별도로 리워드 모델이 필요하지 않고 강화학습을 사용하지도 않습니다. 따라서 훨씬 쉽고 빠르게 모델에 사림의 선호를 반영할 수 있습니다. 현재 2024년 기준 RLHF보다 더 많이 사용되는 선호 학습 기술이라고 합니다.
여기까지 말 잘듣는 LLM을 만들기 위한 여러 방법들을 알아보았습니다. DPO 실습을 통해 RLHF와 비교한 학습 시간이나 성능 차이를 체감해 보고 싶습니다. 추후 실습 결과를 포스팅하며 실제로 느낀 장단점을 공유하겠습니다. 긴 글 읽어주셔서 감사합니다.
댓글남기기