Context Engineering: Manus가 공개한 프로덕션 AI Agent 설계의 핵심
들어가며
최근 LangChain과 Manus가 공동으로 진행한 웨비나에서 Context Engineering에 대한 깊이 있는 논의가 있었습니다. Manus의 공동창업자이자 Chief Scientist인 Peak이 직접 프로덕션 환경에서 얻은 실전 노하우를 공유했는데요, AI Agent를 개발하는 입장에서 매우 유익한 내용이었습니다.
이 글에서는 웨비나의 핵심 내용을 정리하고, 개인적인 인사이트를 덧붙여 공유하고자 합니다.
Context Engineering이란?
Andrej Karpathy가 올해 초 트위터에서 처음 언급한 개념으로, 그는 이렇게 정의했습니다:
“Context Engineering은 LLM이 다음 단계에서 올바른 결정을 내릴 수 있도록, Context Window에 딱 필요한 정보만 채우는 섬세한 기술이자 과학이다.”
핵심은 “just the right information”입니다. 너무 많아도, 너무 적어도 안 됩니다.
Prompt Engineering에서 Context Engineering으로
Google Trends를 보면 흥미로운 패턴이 보입니다:
- Prompt Engineering: ChatGPT 출시(2022년 12월) 이후 급부상
- Context Engineering: 2024년 5월경부터 급부상 (“Year of Agents”)
왜 이런 변화가 생겼을까요? Chat 모델 시대에는 단일 프롬프트를 잘 작성하는 것이 중요했습니다. 하지만 Agent 시대에는 상황이 다릅니다. Agent는 도구를 호출하고, 그 결과를 받고, 다시 판단하는 과정을 반복합니다. 이 과정에서 Context는 계속 누적됩니다.
단순히 프롬프트 하나를 잘 쓰는 것으로는 해결되지 않는 문제가 생긴 것입니다.
왜 Context Engineering이 필요한가
Agent의 Context 폭발 문제
Agent를 만들어보신 분들은 공감하실 겁니다. LLM에 도구(Tool)를 연결하면, Agent는 자율적으로 도구를 호출하고 결과를 받습니다. 문제는 매 호출마다 결과가 메시지 히스토리에 쌓인다는 것입니다.
Manus에 따르면 일반적인 작업에 약 50번의 도구 호출이 필요하고, Anthropic은 프로덕션 Agent가 수백 턴의 대화를 처리한다고 언급했습니다. 웹 검색 결과, 파일 내용, API 응답 등 토큰이 많은 결과들이 계속 쌓이면 Context Window는 순식간에 폭발합니다.
Context Rot 현상 (성능 저하)
더 심각한 문제는 Context가 길어질수록 모델 성능이 떨어진다는 것입니다. 이를 Context Rot이라고 부릅니다.
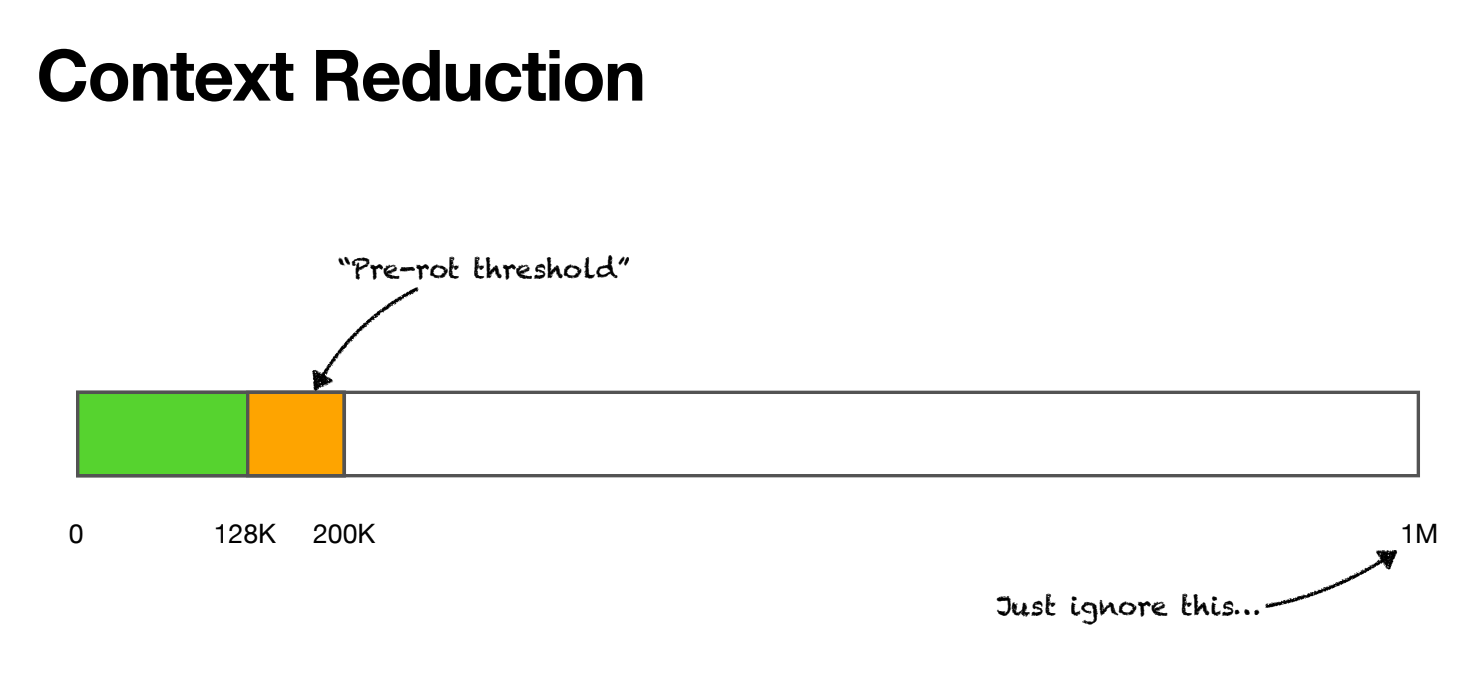
현재 대부분의 모델이 100만 토큰을 지원하지만, 실제로는 128K~200K 토큰 정도에서 성능 저하가 시작됩니다. Manus는 이 임계점을 “Pre-rot threshold”라고 부르며, 이 지점을 정확히 파악하는 것이 중요하다고 강조했습니다.
Context가 길어지면 다음과 같은 현상이 발생합니다:
- 반복적인 출력
- 추론 속도 저하
- 출력 품질 저하
결국 역설적인 상황이 발생합니다:
- Agent는 도구 호출 때문에 Context가 필연적으로 길어지고
- 하지만 Context가 길어지면 성능이 떨어진다
이 딜레마를 해결하는 것이 바로 Context Engineering입니다.
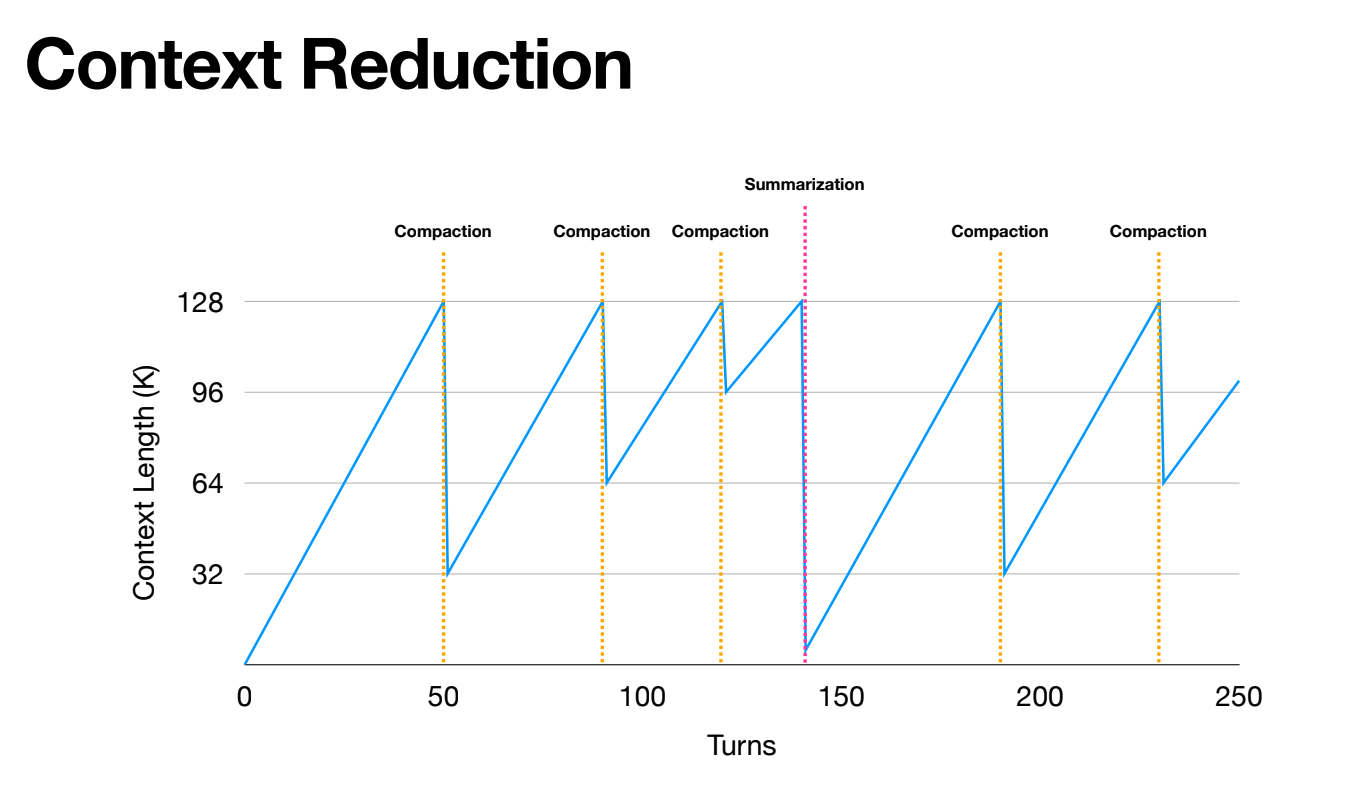
위 그래프는 Manus가 Context를 관리하는 방식을 보여줍니다. Context가 임계점(128K)에 도달하면 Compaction을 수행하고, 여러 번의 Compaction으로도 충분하지 않을 때 Summarization을 수행합니다. 이렇게 Context 길이를 일정 범위 내로 유지하면서 장기 실행 Agent를 안정적으로 운영할 수 있습니다.
Context Engineering 5가지 핵심 전략
웨비나에서 소개된 Context Engineering의 핵심 전략은 5가지입니다. 각 전략은 독립적이지 않고 서로 연결되어 있습니다.
Context Offloading (외부로 분리)
핵심 아이디어: 모든 정보를 메시지 히스토리에 담을 필요가 없습니다. 파일 시스템 등 외부 저장소로 분리하고, 필요할 때만 가져오면 됩니다.
예를 들어, 웹 검색 결과가 10,000 토큰이라면:
- Before: 전체 결과를 메시지에 저장 → Context 폭발
- After: 파일로 저장하고 경로만 메시지에 남김 → 필요시 파일 읽기
이 방식은 Claude Code, Manus, Open Deep Research 등 대부분의 프로덕션 Agent에서 사용됩니다.
Context Reduction (압축/요약)
Context를 줄이는 방법은 크게 두 가지입니다:
| 방식 | 특징 | 복원 가능 |
|---|---|---|
| Compaction | 불필요한 필드 제거 (예: 파일 내용 → 경로만 유지) | O |
| Summarization | 전체 내용을 요약 | X |
Manus는 Compaction을 우선 적용합니다. 왜냐하면 Agent는 이전 행동을 기반으로 다음 판단을 하는데, 어떤 과거 정보가 중요해질지 예측할 수 없기 때문입니다. Compaction은 복원 가능하므로 정보 손실 위험이 없습니다.
Summarization은 Compaction만으로 충분하지 않을 때 사용하며, 이때도 전체 히스토리를 파일로 백업해두어 필요시 복구할 수 있게 합니다.
Context Retrieval (검색)
Offloading한 정보를 다시 가져오는 방법입니다. 현재 두 가지 접근법이 있습니다:
1. 시맨틱 검색 (Indexing + Vector Search)
- Cursor가 사용하는 방식
- 의미 기반 검색 가능
2. 파일 시스템 + 단순 검색 도구 (glob, grep)
- Claude Code가 사용하는 방식
- 인덱싱 오버헤드 없음, 빠른 시작
Manus는 후자를 선택했습니다. 매 세션마다 새로운 샌드박스를 생성하기 때문에 인덱스를 빌드할 시간이 없고, 모델이 충분히 똑똑하다면 grep과 glob만으로도 원하는 정보를 찾을 수 있기 때문입니다.
Context Isolation (분리)
핵심 아이디어: Sub-agent를 활용해 Context를 분리합니다. 각 Sub-agent는 독립적인 Context Window를 가지므로, 메인 Agent의 Context가 오염되지 않습니다.
Go 언어 커뮤니티의 유명한 격언이 있습니다:
“메모리를 공유하여 통신하지 말고, 통신을 통해 메모리를 공유하라.”
이를 Agent에 적용하면 두 가지 패턴이 나옵니다:
1. By Communicating (메시지 전달)
- 메인 Agent가 명확한 지시를 Sub-agent에 전달
- Sub-agent는 결과만 반환
- 예: “이 코드베이스에서 특정 함수 찾아줘”
2. By Sharing Memory (Context 공유)
- Sub-agent가 전체 히스토리에 접근 가능
- 복잡한 작업에 적합
- 예: Deep Research에서 중간 검색 결과를 모두 참조해야 할 때
상황에 따라 적절한 패턴을 선택해야 합니다.
Context Caching (캐싱)
LLM API의 KV Cache를 효율적으로 활용하는 전략입니다. Anthropic의 Input Caching 같은 기능을 활용하면 비용과 지연 시간을 크게 줄일 수 있습니다.
주의할 점은 도구 정의가 Context 앞부분에 위치한다는 것입니다. 도구를 동적으로 추가/제거하면 KV Cache가 무효화됩니다. 그래서 Manus는 도구를 고정하고, 확장 기능은 샌드박스 내 유틸리티로 처리합니다.
Manus의 실전 노하우
이 섹션에서는 웨비나에서 Peak이 공유한 Manus만의 실전 노하우를 정리합니다.
Compaction vs Summarization의 차이
앞서 간단히 언급했지만, Manus의 접근법을 더 자세히 살펴보겠습니다.
Compaction 예시:
파일 쓰기 도구의 결과를 생각해봅시다.
// Full format
{ "path": "/app/main.py", "content": "... 1000줄의 코드 ..." }
// Compact format
{ "path": "/app/main.py" }
파일이 이미 저장되었으므로, content 필드는 제거해도 됩니다. 모델이 나중에 필요하면 경로로 다시 읽으면 됩니다.
Compaction 적용 시 주의사항:
- 전체 히스토리를 Compaction하지 않습니다
- 최근 50%는 Full format 유지 → 모델이 도구 사용법을 잊지 않도록
- 오래된 50%만 Compact format으로 변환
Summarization 적용 시 주의사항:
- 자유 형식(free-form) 요약은 피합니다
- 구조화된 스키마를 사용합니다:
- 수정한 파일 목록
- 사용자 목표
- 현재 진행 상황
- 요약 전 전체 히스토리를 파일로 백업
- 요약 후에도 최근 몇 개의 도구 호출은 Full format 유지
3단계 Action Space (Function Call / Sandbox / Code)
Manus의 가장 흥미로운 설계 중 하나입니다. 도구가 너무 많으면 모델이 혼란스러워하고 잘못된 도구를 호출하는 Context Confusion 문제가 발생합니다.
Manus는 이를 3단계로 해결합니다:
Level 1: Function Calling (10~20개 고정)
가장 기본적인 원자적(atomic) 함수들:
- 파일 읽기/쓰기
- 셸 명령 실행
- 브라우저 조작
- 인터넷 검색
이 도구들은 고정되어 있어 KV Cache 효율이 좋습니다.
Level 2: Sandbox Utilities
Manus는 가상 머신(VM) 샌드박스에서 실행됩니다. 셸 명령으로 호출 가능한 사전 설치된 유틸리티들:
- 포맷 변환기
- 음성 인식
- MCP CLI (MCP 도구를 Function Calling이 아닌 CLI로 호출!)
새 기능 추가 시 Function Calling 스키마를 건드릴 필요가 없습니다. 그냥 유틸리티를 설치하면 됩니다. 모델은 --help 플래그로 사용법을 파악할 수 있습니다.
Level 3: Packages & APIs (Code)
Python 스크립트로 API 호출이나 복잡한 연산 수행:
- 금융 데이터 API
- 3D 모델링 라이브러리
- 대량 데이터 처리
예를 들어, 1년치 주가 데이터를 분석한다면 전체 데이터를 Context에 넣는 것보다 Python 스크립트로 처리하고 결과 요약만 반환하는 것이 훨씬 효율적입니다.
Code는 composable합니다. 여러 API 호출을 하나의 스크립트로 묶을 수 있어 도구 호출 횟수를 줄일 수 있습니다.
3단계 모두 결국 Function Calling을 통해 실행됩니다:
- Level 2 →
shell함수로 유틸리티 실행 - Level 3 →
file함수로 스크립트 작성 후shell로 실행
모델 입장에서는 익숙한 인터페이스를 유지하면서, 실제로는 무한히 확장 가능한 구조입니다.
Sub-agent 통신 패턴: 공유 vs 메시지 전달
Manus의 Wide Research 기능은 내부적으로 Agentic MapReduce라고 부릅니다.
핵심 설계:
- 메인 Agent가 Sub-agent 생성 시 출력 스키마를 정의
- Sub-agent는
submit_result도구로 결과 제출 - Constrained Decoding으로 스키마 준수 보장
- 결과는 스프레드시트처럼 구조화됨
이렇게 하면 Sub-agent들의 출력이 일관되고, 메인 Agent가 결과를 쉽게 통합할 수 있습니다.
파일 시스템을 통한 Context 공유:
Manus의 모든 Sub-agent는 동일한 샌드박스를 공유합니다. 따라서:
- 메인 Agent가 파일에 정보 저장
- Sub-agent에게 파일 경로만 전달
- Sub-agent가 필요한 정보를 파일에서 읽음
이 방식은 Context를 직접 복사하는 것보다 효율적입니다.
인사이트: Context Over-Engineering을 경계하라
웨비나에서 Peak이 마지막으로 강조한 내용이 인상적이었습니다.
“지난 6~7개월간 Manus에서 가장 큰 성능 향상은 복잡한 Context 관리 기법을 추가해서가 아니라, 불필요한 트릭을 제거하고 모델을 더 신뢰하면서 얻었습니다.”
모델을 믿고 단순화하기
Context Engineering의 목표는 모델의 작업을 더 쉽게 만드는 것이지, 더 어렵게 만드는 것이 아닙니다.
너무 많은 레이어를 추가하면:
- 시스템이 복잡해지고
- 디버깅이 어려워지며
- 오히려 성능이 떨어질 수 있습니다
Manus는 3월 런칭 이후 5번의 대규모 리팩토링을 거쳤다고 합니다. 매번 단순화할 때마다 시스템이 더 빠르고, 안정적이고, 똑똑해졌다고 합니다.
아키텍처 검증법: 약한 모델 ↔ 강한 모델 스위칭
Peak이 공유한 흥미로운 검증 방법입니다:
“아키텍처를 고정하고, 약한 모델에서 강한 모델로 바꿨을 때 성능이 크게 향상된다면, 그 아키텍처는 미래에도 유효합니다.”
왜냐하면:
- 오늘의 강한 모델 = 내일의 약한 모델
- 모델 발전에 따라 자연스럽게 성능이 올라가는 구조
반대로, 특정 모델에 과도하게 최적화된 아키텍처는 모델이 바뀌면 무용지물이 될 수 있습니다.
마무리
이번 웨비나를 통해 Context Engineering에 대한 체계적인 이해를 얻을 수 있었습니다. 핵심을 정리하면:
5가지 전략:
- Offloading - 파일 시스템으로 분리
- Reduction - Compaction 우선, Summarization은 최후의 수단
- Retrieval - 상황에 맞는 검색 방식 선택
- Isolation - Sub-agent로 Context 분리
- Caching - KV Cache 효율 고려
Manus의 교훈:
- 도구는 고정하고 확장성은 샌드박스로
- 스키마 기반 구조화된 출력
- 복잡함보다 단순함
가장 중요한 것:
- Context Engineering은 모델을 돕는 것이지, 대체하는 것이 아닙니다
- 모델이 발전하면 불필요해질 트릭은 과감히 제거하세요
Agent 개발을 하시는 분들께 이 글이 도움이 되었으면 좋겠습니다.
댓글남기기