GPU 효율적인 학습
LLM을 다룰 때 필연적으로 맞이하는 문제가 GPU관련 문제입니다. 이번 포스팅에서는 GPU를 효율적으로 사용해 모델을 학습시키는 다양한 기술을 살펴보겠습니다.
GPU 메모리 기초
- 데이터 타입과 메모리 사용량
- 딥러닝 연산 시 메모리 사용 패턴
단일 GPU 최적화 기법
- 그레디언트 누적 (Gradient Accumulation)
- 그레디언트 체크포인팅 (Gradient Checkpointing)
다중 GPU 학습 최적화
- 분산 학습 기초
- DeepSpeed ZeRO: 효율적인 메모리 관리
파라미터 효율적 학습 기법
- LoRA (Low-Rank Adaptation)
- QLoRA: 양자화를 통한 메모리 최적화
이어지는 내용에서 각 기술에 대해 자세히 살펴보도록 하겠습니다.
1. GPU에 올라가는 데이터 살펴보기
GPU를 사용할 때 가장 자주 만나는 에러 중 하나는 OOM(Out of Memory)입니다. 이 에러는 GPU 메모리가 부족해 모델을 학습시킬 수 없음을 의미합니다. 이런 문제를 해결하기 위해서는 먼저 GPU에 올라가는 데이터 타입과 그 데이터가 차지하는 메모리 사용량을 알아야합니다. 기본적으로 GPU에는 딥러닝 모델 자체가 올라갑니다. 모델은 수많은 행렬 곱셈을 위한 파라미터의 집합인데 각각의 파라미터는 소수 또는 정수 형식의 숫자입니다. 이번 챕터에서는 모델의 파라미터가 어떤 형식의 숫자로 모델을 구성하는지 살펴보고 모델의 용량을 줄이기 위한 방법인 양자화에 대해서도 알아보겠습니다.
1.1 데이터 타입
컴퓨터는 일반적으로 소수 연산을 위해 32비트 부동소수점(float32)을 사용합니다. 만약 더 세밀한 계산이 필요하다면 64비트 부동소수점(float64)을 사용합니다. 이 부동소수점을 나타내는 비트의 수가 커질수록 표현할 수 있는 수의 범위나 세밀한 정도가 달라지죠. 모델은 입력한 데이터를 최종 결과로 산출할 때까지 많은 행렬 곱셈에 사용되는 파라미터로 구성됩니다. 예를 들어 파라미터가 70억개인 LLM은 70억개의 파라미터가 저장됩니다. 따라서 LLM 모델의 용량은 모델을 몇 비트의 데이터 형식으로 표현하는지에 따라 달라집니다.
과거에는 모델을 32비트 부동소수점 형식을 사용해 저장했습니다. 하지만 성능을 높이기 위해 점점 더 큰 모델을 사용하면서 GPU에 올리지 못하거나 계산이 너무 오래 걸리는 문제가 생겼습니다. 때문에 최근에는 주로 16비트로 수를 표현하는 fp16또는 bf16을 주로 사용합니다. 아래 그림에서 fp32와 fp16, bf16을 비교하고 있습니다. 그림에서 S는 부호, E는 지수, M은 가수를 의미합니다. 지수는 수를 표현할 수 있는 범위의 크기를 결정하고 가수는 표현할 수 있는 수의 촘촘함을 결정합니다.
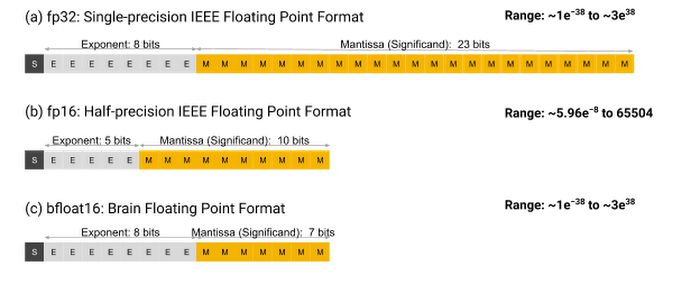
모델은 학습과 추론 같은 모델 연산 과정에서 GPU 메모리에 올라가기 때문에, 모델의 용량이 얼마인지가 GPU 메모리 사용량을 체크할 때 중요합니다. 딥러닝 모델의 용량은 파라미터 수에 마라미터당 비트 수를 곱하면 됩니다. 예를 들어 7B 모델이 16비트 데이터 형식으로 저장된다면 모델의 용량은 7 x 2 = 14GB가 됩니다.
1.2 양자화로 모델 용량 줄이기
모델 파라미터의 데이터 타입이 더 많은 비트를 사용할수록 모델의 용량이 커지기 때문에 더 적은 비트로 모델을 표현하는 양자화 기술이 등장했습니다. 예를 들어 fp32로 저장하던 모델을 fp16 형식으로 저장하면 모델의 용량은 절반이 됩니다. 하지만 fp32가 fp16에 비해 더 넓은 범위의 수를 더 세밀하게 표현할 수 있기 때문에 fp16로 저장하면 모델의 성능이 떨어질 수 있습니다. 양자화를 수행하면 모델의 성능의 저하되기에 양자화 기술에서는 더 적은 비트를 사용하면서도 원본 데이터의 정보를 최대한 소실 없이 유지하는 것이 핵심 과제라고 할 수 있습니다.
원본 데이터의 정보를 최대한 유지하면서 더 적은 용량의 데이터 형식으로 변환하려면, 변환하려는 데이터 형식의 수를 최대한 낭비하지 않고 사용해야 합니다.
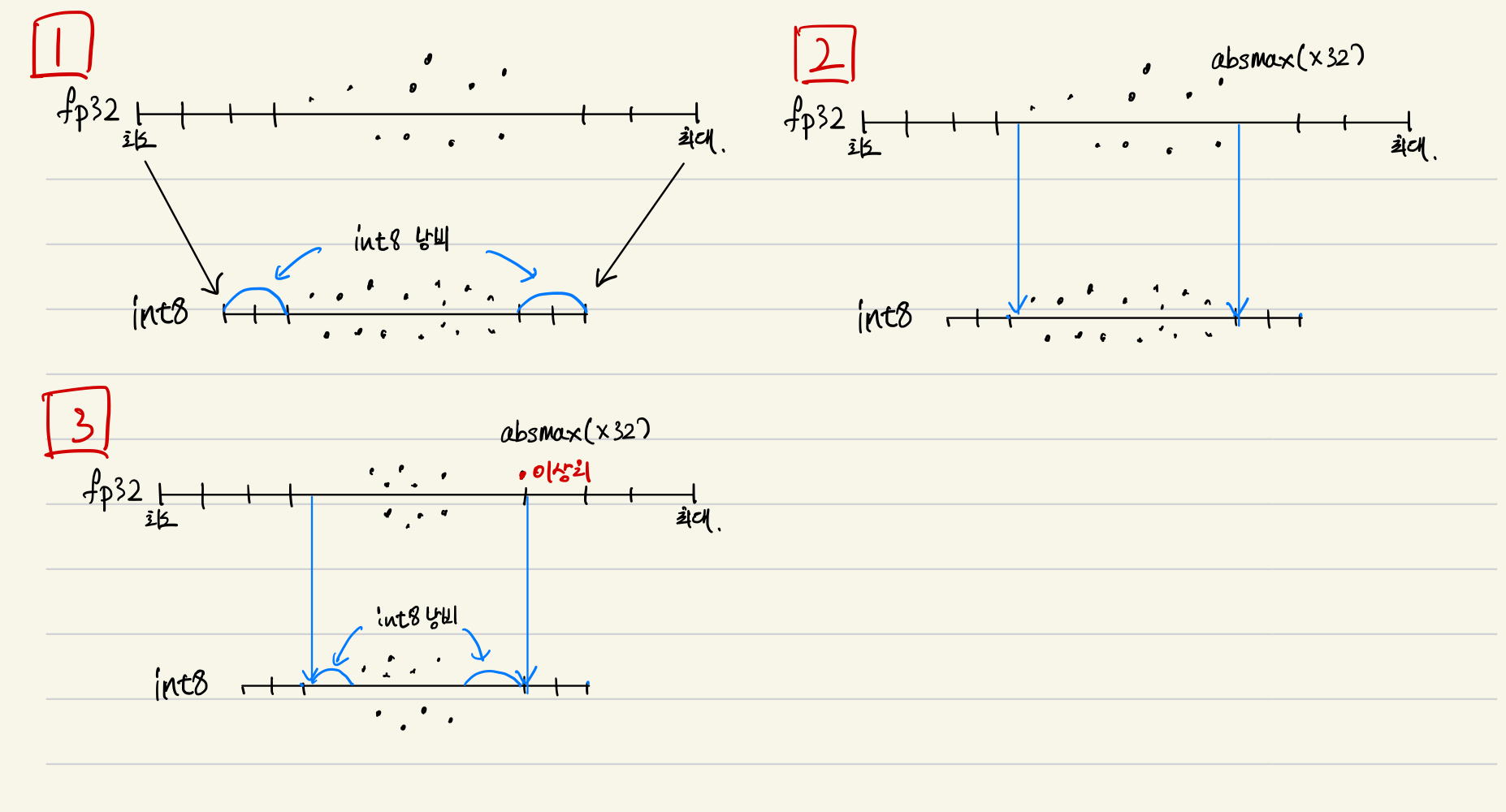
위 그림의 1번과 같이 fp32의 데이터를 int8로 변환한다고 할 때, fp32는 하나의 수를 표현하기 위해 32비트나 사용하지만 int8은 8비트만 사용하기에 사용할 수 있는 수가 훨씬 적습니다. int8의 경우 256개의 수만 표현할 수 있기 때문에 256개 수 가운데 사용되지 않는 수를 줄여야 합니다. 1번그림에서는 두 데이터 형식의 최대, 최솟값을 각각 대응시키는 간단한 방식으로 양자화를 했습니다. 이 때 int8의 양쪽 끝 수는 사용하는 데이터가 없이 존재해 낭비되는 문제가 발생합니다.
이러한 낭비를 줄이기 위해 2번그림과 같이 데이터 형식 자체의 최대, 최소를 대응시키는 것이 아니라 존재하는 데이터의 최댓값 범위로 양자화하는 방법도 있습니다. 하지만 이 방법은 이상치가 있는 경우 취약합니다. 3번그림처럼 이상치가 있는 경우 최댓값이 이상치에 의해 정해지기 때문에 대부분의 데이터가 중앙에 모여있고 int8의 범위 양쪽 수를 사용하지 못하는 낭비가 발생합니다.
지금까지 더 적은 비트를 사용하는 데이터 타입으로 변환하면서도 원본 데이터의 정보를 최대한 유지한다는 양자화의 목표와 여러 접근 방법을 알아봤습니다.
댓글남기기